기존 sequence transduction model → 복잡한 recurrent나 cnn 기반
가장 성능이 좋은 모델 → attention mechanism으로 인코더와 디코더를 연결한 구조
Recurrent model → parallelization이 불가능해 longer sequence length에서 치명적임
- 최근 factorization trick과 conditional computation을 통해 계산 효율성 개선
- 특히 conditional computation은 모델 성능도 동시에 개선
- 그러나 여전히 근본적인 sequential computation의 문제는 남아있음
Attention mechanism → 다양한 분야의 sequence modeling과 transduction model에서 주요
- Attention mechanism은 input과 output sequence간 길이를 신경쓰지 않아도 됨
- 하지만 여전히 recurrent network와 함께 사용되었음
📌 Transformer
온전히 self-attention에만 의존한 최초의 transduction model(recurrence나 convolution 사용X) → 더 parallelizable하고, 훨씬 적은 학습 시간이 걸림
- input과 output간 global dependency를 뽑아내기 위해 recurrence를 사용하지 않고, attention mechanism만을 사용
- parallelization이 가능해 적은 시간으로 translation quality에서 SOTA를 달성할 수 있었음
📌 sequential computation 감소 → Extended Neural GPU, ByteNet, ConvS2S에서도 다룸
- 이 연구들은 모두 CNN을 basic building block으로 사용함
- input output 거리에서 dependency를 학습하기 어려움
- Transformer에서는 Multi-Head Attention으로 상수 시간으로 줄어듦
📌 End-to-end memory network
- sequence-aligned recurrence 보다 recurrent attention mechanism에 기반함
- simple-language question answering 과 language modeling task에서 좋은 성능을 보임
Encoder and Decoder Stacks

📌 Encoder
- 6개의 identical layer로 구성
- 각 layer는 두 개의 sub-layer를 가짐
- 첫 번째 sub-layer → multi-head self-attention mechanism
- 두 번째 sub-layer → position-wise fully connected feed-forward network
- 각 two sub-layers 마다 layer normalization 후에 residual connection 사용
- residual connection을 구현하기 위해, 모든 sub-layer들의 output → 512 차원
📌 Decoder
- 6개의 identical layer로 구성
- 각 Encoder layer의 두 sub-layer에, decoder는 세번째 sub-layer 추가
- encoder stack의 결과에 해당 layer가 multi-head attention 수행
- 마찬가지로 residual connection 적용
📌 Attention

쿼리와 key-value쌍을 output에 매핑(query,key,value,output은 모두 vector)
output은 value들의 weighted sum으로 계산됨
Scaled Dot-Product Attention
- Additive attention single hidden layer로 feed-forward layer network를 사용해 compatibility function 계산
- Dot-product attention scaling factor (1√dk) 를 제외하면 이 연구에서의 attention 방식과 동일
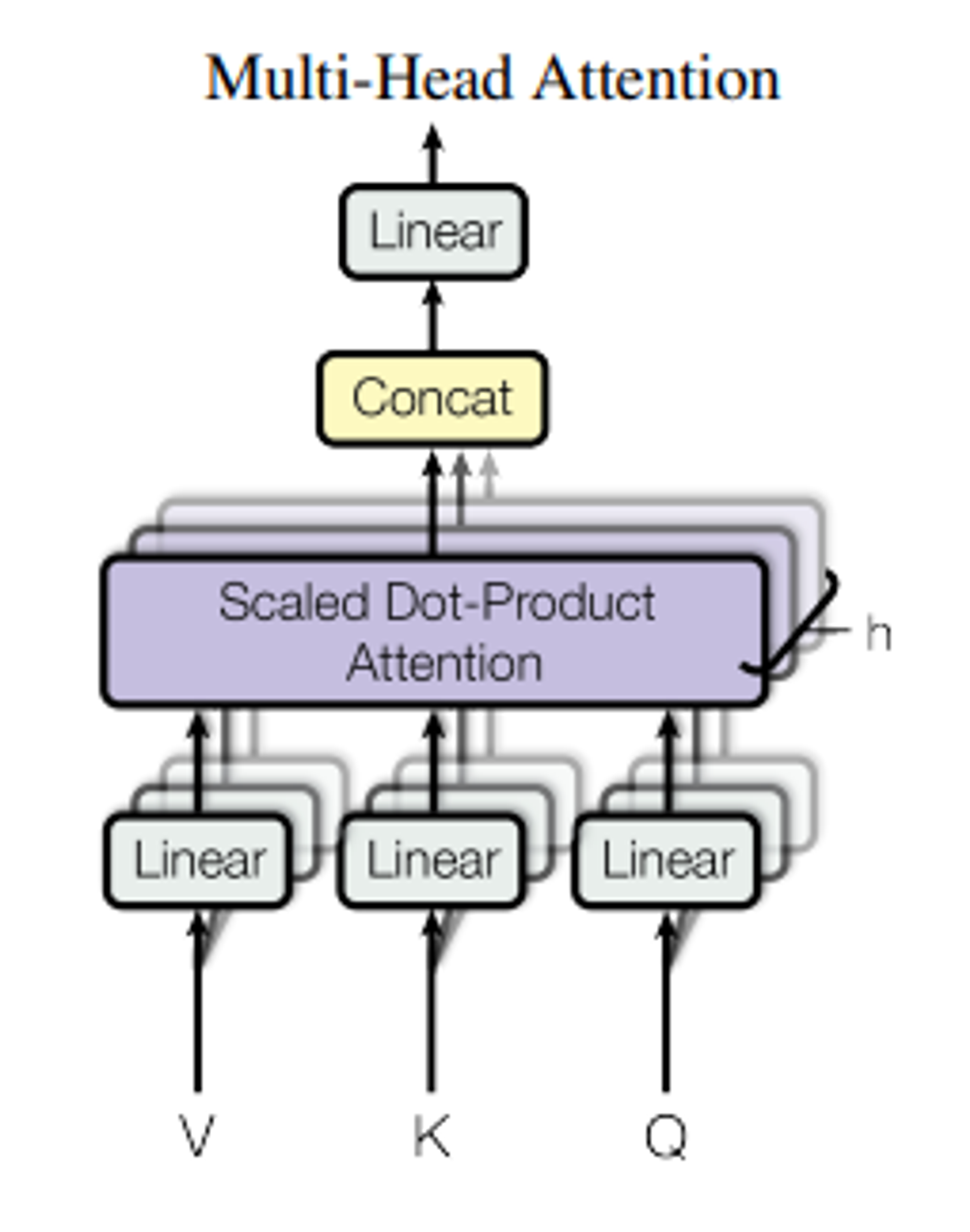
Multi-Head Attention
- Single attention을 queries, keys, values를 h번 서로 다른, 학습된 linear projection으로 linear하게 project하는 게 더 효과적이라는 사실을 알아냄 → project된 각 값들은 병렬적으로 attention function을 거쳐 dvdimensional output value를 만들어 냄 → 이 결과들은 다시 합쳐진 다음, 다시 한번 project 되어 최종 결과 값을 만듦 → 각 head마다 차원을 줄이기 때문에, 전체 계산 비용은 전체 차원에 대한 single-head attention과 비슷함
📌 Applications of Attention in our Model
Transformer는 세 가지 방법으로 multi-head attention 사용
인코더-디코더 attention layers
- query는 이전 디코더 layer에서 나옴
- memory key와 value는 인코더의 output에서 나옴
- 따라서 디코더의 모든 position이 input sequence의 모든 position을 다룸
- 전형적인 sequence-to-sequence model에서의 인코더-디코더 attention 방식
인코더는 self-attention layer를 포함
- self-attention layer에서 key, value, query는 모두 같은 곳(인코더의 이전 layer의 output)에서 나옴
- 인코더의 각 position은 인코더의 이전 layer의 모든 position을 다룰 수 있음
디코더 또한 self-attention layer를 가짐
- 마찬가지로, 디코더의 각 position은 해당 position까지 모든 position을 다룰 수 있음
- 디코더의 leftforward information flow는 auto-regressive property 때문에 막아줘야 할 필요가 있음 → 이 연구에서는 scaled-dot product attention에서 모든 softmax의 input value 중 illegal connection에 해당하는 값을 −∞로 masking out해서 구현
📌 Position-wise Feed-Forward Networks
인코더 디코더의 각 layer는 fully connected feed-forward network를 가짐
- 각 position에 따로따로, 동일하게 적용
- ReLu 활성화 함수를 포함한 두 개의 선형 변환 포함
Embeddings and Softmax
다른 sequence transduction models 처럼, 학습된 임베딩 사용
- input 토큰과 output 토큰을 dmodel 의 벡터로 변환하기 위함
decoder output을 예측된 다음 토큰의 확률로 변환하기 위해 선형 변환과 softmax를 사용
- tranformer에서는, 두 개의 임베딩 layer와 pre-softmax 선형 변환 간, 같은 weight의 matrix를 공유
Positional Encoding
Transformer는 어떤 recurrene, convolution도 사용하지 않기 때문에, sequence의 순서를 사용하기 위해 sequence의 상대적, 절대적 position에 대한 정보를 주입해줘야
인코더와 디코더 stack 아래의 input 임베딩에 "Positional Encoding"을 추가함
📌 Why Self-Attention
Convolution layer는 일반적으로 recurrent layer보다 더 비용이 많이 듦
- Separable Convolution의 경우 복잡도를 O(knd+nd2) 까지 줄일 수 있음
- 그러나 k=n 의 경우, transformer 와 같이 self-attention layer와 point-wise feed forward layer의 조합과 복잡도가 같음
self-attention은 더 interpretable한 모델을 만들 수 있음
- attention distribution에 대해 다룸 (논문의 Appendix 참고)
- 각 attention head들은 다양한 task를 잘 수행해내고, 문장의 구문적, 의미적 구조를 잘 연관시키는 성질을 보이기도 함
Reference
[논문 리뷰] Transformer 논문 리뷰 (Attention Is All You Need)
Transformer 논문 리뷰 - ChatGPT 모델의 근간 확실하게 이해하기
[Transformer 논문 리뷰] - Attention is All You Need (2017)
[논문리뷰] Transformer (Attention Is All You Need)
'Research Review' 카테고리의 다른 글
| [LLM] A Comprehensive Analysis of the Effectiveness of Large Language Models as Automatic Dialogue Evaluators (0) | 2024.05.07 |
|---|---|
| [LLM] LLMEval: A Preliminary Study on How to Evaluate Large Language Models (0) | 2024.05.07 |
| [MultiModal] DDPM: Denoising Diffusion Probabilistic Models (0) | 2024.05.07 |
| [MultiModal] VAE: Auto-Encoding Variational Bayes (0) | 2024.05.07 |
| [MultiModal] StyleGAN (0) | 2024.05.07 |


